Usage
Learn how to use MCP Jupyter effectively with your AI assistant.
Basic Usage
Creating a New Notebook
Ask your AI assistant to create a notebook:
"Create a new notebook called data_analysis.ipynb"
The AI will:
- Create the notebook file
- Start a kernel
- Be ready for your commands
Working with Existing Notebooks
"Open the notebook experiments/model_training.ipynb"
Your AI assistant will connect to the existing notebook and preserve all current state.
Key Features
State Preservation
All variables, data, and models remain available throughout your session. Work with large datasets without reloading, and hand off complex objects between you and the AI.
Automatic Error Recovery
The AI sees execution errors in real-time and can automatically install missing packages, fix syntax issues, or suggest corrections.
Seamless Collaboration
Switch between manual exploration and AI assistance at any point. The AI builds on your work, and you can take over whenever needed.
Smart Package Management
Missing dependencies are automatically detected and installed, so your workflow isn't interrupted by import errors.
Common Use Cases
MCP Jupyter excels at collaborative data work. Here are popular use cases:
Data Analysis & Exploration
- Data cleaning & profiling: "Handle missing values, outliers, and analyze data quality"
- Exploratory analysis: "Show me key patterns, distributions, and statistical summaries"
- Trend analysis: "Plot time series trends with seasonality and correlations"
Machine Learning & Modeling
- End-to-end ML pipeline: "Prepare data, engineer features, and compare multiple algorithms"
- Model optimization: "Tune hyperparameters and evaluate performance comprehensively"
- Experiment analysis: "Analyze A/B tests and statistical significance"
Data Visualization & Reporting
- Automated visualization: "Create appropriate charts and statistical plots for this data"
- Custom dashboards: "Build interactive visualizations and reports"
- Anomaly detection: "Identify and visualize unusual patterns"
Research & Advanced Analysis
- Hypothesis testing: "Test statistical differences and relationships between variables"
- Cohort & behavioral analysis: "Track user patterns and segment analysis over time"
- Concept exploration: "Demonstrate and compare different analytical methods"
Workflow Automation
- Data pipelines: "Create repeatable ETL processes and data validation workflows"
- Report automation: "Generate recurring analysis reports with charts and summaries"
- Code assistance: "Debug analysis code and explain complex statistical concepts"
Best Practices
1. Clear Instructions
Be specific about what you want:
- ❌ "Analyze the data"
- ✅ "Perform exploratory data analysis focusing on customer segments and seasonal patterns"
2. Specify Cell Types Clearly
Help the AI choose the right cell type and operation:
- For code: "Add a code cell that loads the data"
- For markdown: "Create a markdown cell with the project title and description"
- For mixed content: "Add a markdown cell explaining the analysis, then add code to implement it"
3. Handle Operation Errors
Common AI mistakes and corrections:
- ❌ AI says "edit_markdown" → ✅ Should be
operation="add_markdown"oroperation="edit_markdown" - ❌ Putting ASCII art in code cells → ✅ "Put that ASCII art in a markdown cell instead"
- ❌ IndentationError on non-code content → ✅ "That content belongs in markdown, not code"
4. Iterative Refinement
Work iteratively with the AI:
1. "Load and preview the customer data"
2. Review the output
3. "Focus on customers from the last quarter"
4. "Now segment them by purchase frequency"
5. State Management
- Keep important variables in the global namespace
- Use descriptive variable names
- Periodically check available variables with
dir()orlocals()
6. Error Recovery
When errors occur:
- Let the AI see and handle the error
- Clarify cell type if there's confusion: "That should be markdown, not code"
- Provide context if needed
- The AI will install packages or fix issues automatically
Demo Example
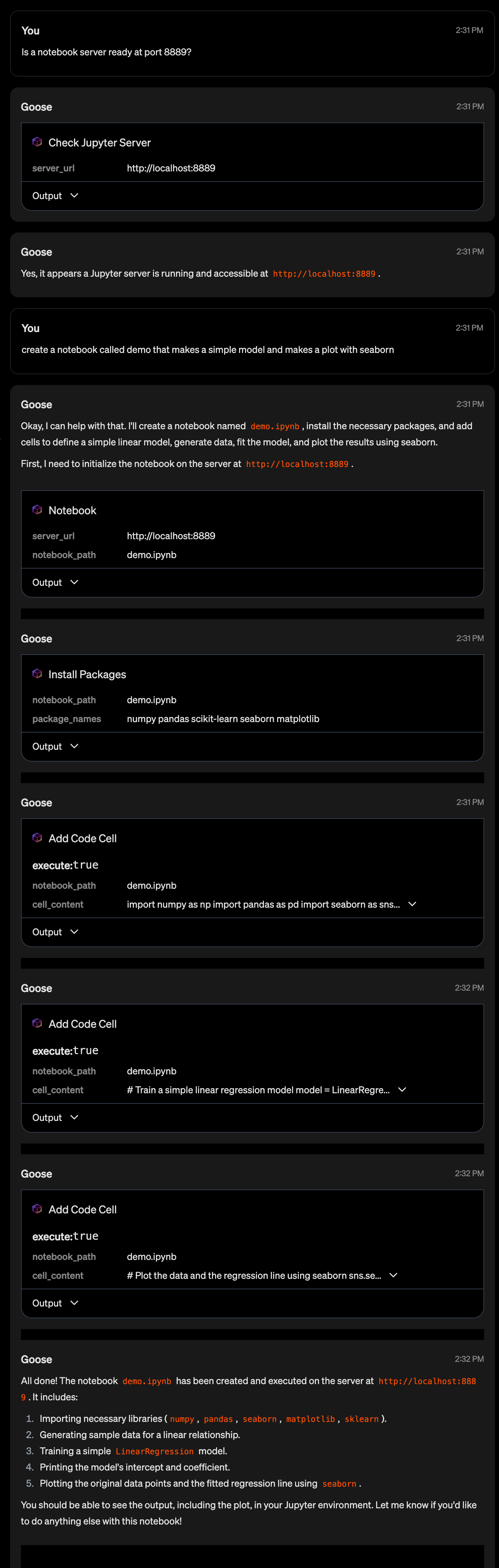
Tips and Tricks
- Use Markdown cells: Ask the AI to document its analysis
- Save checkpoints: Periodically save important state
- Combine approaches: Use AI for boilerplate, manually tune details
- Leverage errors: Let errors guide package installation
- Incremental development: Build complex analyses step by step