Streamlining Detection Development with Goose Recipes


Creating effective security detections in Panther traditionally requires deep knowledge of detection logic, testing frameworks, and development workflows. The detection engineering team at Block has streamlined this process by building Goose recipes that automate the entire detection creation lifecycle from initial repository set up to pull request creation.
This blog post explores how to leverage Goose's recipe and subrecipe system to create new detections in Panther with minimal manual intervention, ensuring consistency, quality, and adherence to team standards.
What Are Recipes?
Recipes are reusable, shareable configurations that package up a complete setup for a specific task. These standalone files can be used in automation workflows that orchestrate complex tasks by breaking them into manageable, specialized components. Think of them as sophisticated CI/CD pipelines for AI-assisted development, where each step has clearly defined inputs, outputs, and responsibilities.
Two notable ingredients of recipes are instructions and prompt. In short:
- Instructions get added to the system prompt and defines the agent’s roles and capabilities (influences the AI's behavior and personality)
- The prompt becomes the initial user message with a specific task (starts the conversation)
Snippet from workflow_setup showing the difference
workflow_setup showing the differenceinstructions: |
Create a Panther detection rule that detects: {{ rule_description }}
Use the following context:
- Similar rules found: {{ similar_rules_found }}
- Rule analysis: {{ rule_analysis }}
- Log schemas: {{ log_schemas }}
- Standards summary: {{ standards_summary }}
**SCOPE BOUNDARIES:**
- ...
prompt: |
## Process:
1. **Rule Planning**:
- Follow "📝 Create Rule Files" guidance from `AGENTS.md`
- Use streaming rule type (default) unless otherwise specified
- Choose appropriate log source and severity level
2. **File Creation**:
- ...
...
5. **Test Cases**:
- ...
...
7. **🛑 STOP CONDITION**:
- ...
## ✅ SUCCESS CRITERIA:
- ...
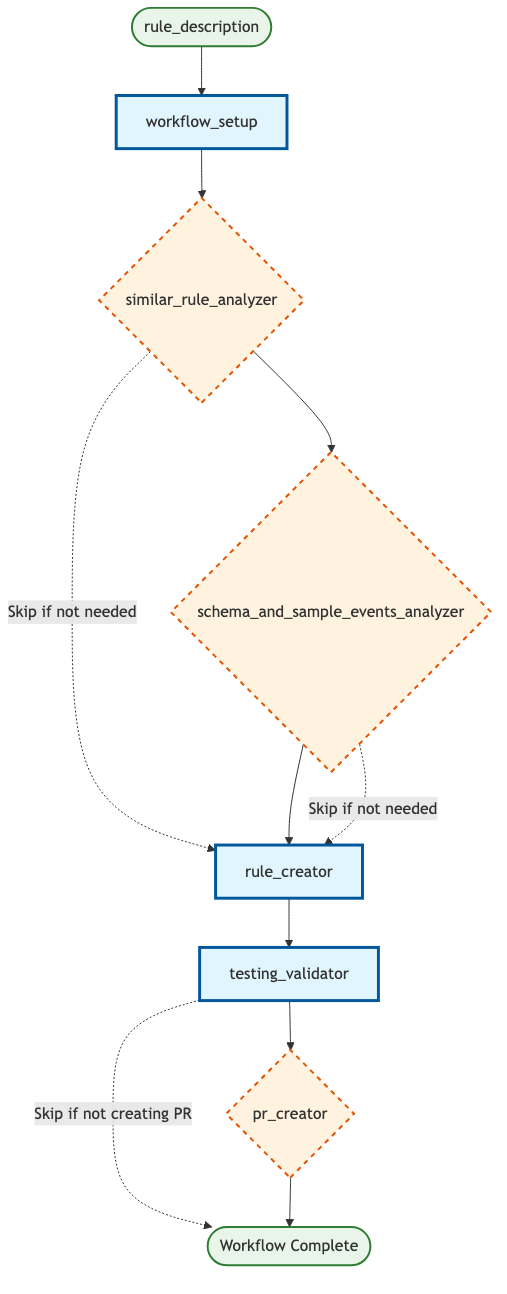
The detection creation recipe demonstrates the power of this approach by coordinating six specialized subrecipes, each handling a specific aspect of detection development:
- workflow_setup - Repository preparation and environment validation
- similar_rule_analyzer - Finding and analyzing existing detection patterns
- schema_and_sample_events_analyzer - Analyzing log schemas and performing sample data collection
- rule_creator - Actual detection rule implementation
- testing_validator - Comprehensive test execution and validation
- pr_creator - Pull request creation with proper formatting
What about .goosehints?
In our previous post, we discussed using .goosehints to provide persistent context to the Large Language Model (LLM). We continue to use .goosehints to define coding standards and universal preferences that guide LLM behavior.
However, to minimize redundancy and avoid conflicting guidance, we adopted a single reference file, AGENTS.md, as the source of truth for all agents. Each agent is directed to consult this file, while still supporting agent-specific instructions through their default context files (e.g. .goosehints, CLAUDE.md etc.) or rules (e.g. .cursor/rules/).
While these context files are important, they also come with some trade offs and limitations:
| Aspect | Context Files | Recipes |
|---|---|---|
| Context window pollution | The entire file is sent with each request, cluttering the context window | Only task-relevant instructions, keeping prompts clear and focused |
| Signal-to-noise ratio | General preferences dilute focus and may create conflicting guidance | Every instruction is workflow-specific, eliminating noise |
| Cost and performance impact | May lead to higher token costs and slower processing from unnecessary context | Pay only for relevant tokens with faster response times |
| Cognitive load on the AI | Conflicting instructions cause decision paralysis | Clear, unified guidance enables decisive action |
| Task-specific optimization | Generic instructions lack specialized tools and parameters | Purpose-built with pre-configured tools for specific workflows |
This centralized approach through AGENTS.md becomes the foundation for our recipe architecture, which we'll explore next.
The Architecture
Design Principles
- Single Responsibility: Each subrecipe has one clear job
- Explicit Data Flow: No hidden state or implicit dependencies
- Fail-Fast: Stop immediately when critical steps fail
- Graceful Degradation: Continue with reduced functionality when possible
- Comprehensive Testing: Validate everything before deployment
Why Subrecipes Matter
The traditional approach to AI-assisted detection creation often involves a single, monolithic prompt (AKA “single-shot prompting”) that tries to handle everything at once. This leads to several problems:
- Context confusion: The AI loses focus when juggling multiple responsibilities
- Inconsistent outputs: Without clear boundaries, results vary significantly (e.g. one subrecipe may try to complete the task that we're expecting another subrecipe to accomplish)
- Difficult debugging: When something fails, it's hard to identify the specific issue
- Poor maintainability: Changes to one aspect affect the entire workflow
The subrecipe architecture solves these problems through strict separation of concerns, setting boundaries and providing exit criteria.
Each subrecipe operates in isolation with:
- Clearly defined inputs and outputs
- Specific scope boundaries (what it MUST and MUST NOT do)
- Standardized JSON response schemas
- Formal error handling patterns
At a high level, a (non-parallel) version would look like:
| Step | Component | Type | Description |
|---|---|---|---|
| 1 | workflow_setup | Required | Initialize workflow environment |
| 2 | similar_rule_analyzer | Conditional | Analyze existing similar rules |
| 3 | schema_and_sample_events_analyzer | Conditional | Process schema and sample data |
| 4 | rule_creator | Required | Generate the detection rule |
| 5 | testing_validator | Required | Validate and test the rule |
| 6 | pr_creator | Conditional | Create pull request |
💡 Note: Conditional steps may be skipped based on workflow configuration
Workflow visualized
Data Flow and State Management
Since subrecipes currently run in isolation, data must be explicitly passed between them. The main recipe orchestrates this flow:
Example of how this would be defined in the recipe:
`workflow_setup(rule_description)` → Returns:
- **branch_name**: Name of the created feature branch
- **standards_summary**: Key standards and requirements from `AGENTS.md`
- **repo_ready**: Boolean indicating if repository is ready for development
- **mcp_panther**: Object containing Panther MCP access test results
- **access_test_successful**: Boolean indicating if Panther MCP access test was successful
- **error_message**: Error message if access test failed
And an example of how the data would flow:
workflow_setup(rule_description) → {
branch_name: "ai/aws-privilege-escalation",
standards_summary: "Key requirements from AGENTS.md...",
repo_ready: true,
mcp_panther: { access_test_successful: true }
}
similar_rule_analyzer(rule_description, standards_summary) → {
similar_rules_found: [...],
rule_analysis: "Analysis of existing patterns...",
suggested_approach: "Create new rule with modifications..."
}
This explicit data passing ensures:
- Predictable behavior across runs
- Easy debugging when issues occur
- Clear audit trails of what data influenced each decision
- Modular testing of individual components
Smart Optimizations: Conditional Execution
One of the most powerful features of the detection creation workflow is its intelligent optimization system that skips unnecessary steps based on both parameters and runtime conditions.
Parameter-Based Conditions
Users can control workflow behavior through parameters:
# Fast mode - skip similar rule analysis
goose run --recipe recipe.yaml --params skip_similar_rules_check=true --rule_description="What you want to detect"
# Skip Panther MCP integration
goose run --recipe recipe.yaml --params skip_panther_mcp=true --rule_description="What you want to detect"
# Create PR automatically
goose run --recipe recipe.yaml --params create_pr=true --rule_description="What you want to detect"
Runtime Conditions
The workflow makes intelligent decisions based on results from previous steps:
# Current implementation uses both parameter-based and runtime conditions
# Parameter-based (available at recipe start):
- skip_similar_rules_check: Controls similar_rule_analyzer execution
- skip_panther_mcp: Controls schema_and_sample_events_analyzer execution
- create_pr: Controls pr_creator execution
# Runtime conditions (based on subrecipe results):
- schema_and_sample_events_analyzer runs only if:
* skip_panther_mcp is false AND
* (similar_rules_found is empty OR mcp_panther.access_test_successful is false)
This hybrid approach provides:
- Efficiency: Avoid redundant API calls when similar rules provide sufficient context
- Reliability: Graceful degradation when external services are unavailable
- Flexibility: Users can choose their preferred speed vs. thoroughness trade-off
Additionally, Jinja support enables the codification of event triggers, ensuring the agent adheres to predefined instructions rather than making independent, potentially incorrect, decisions. For instance, the agent can be directed to bypass a step, depending on a parameter's value:
{% if create_pr %}
6. `pr_creator(rule_files_created, rule_description, branch_name, create_pr={{ create_pr }}, panther_mcp_usage)` → Returns:
{
"success": true,
"data": {
"pr_created": true,
"pr_url": "https://github.com/<org>/<team>-panther-content/pull/123",
"pr_number": 123,
"summary": "Summary of the completed work"
}
}
{% else %}
6. **SKIPPED** `pr_creator` - create_pr parameter is false
- Provide final summary of completed work instead
{% endif %}
Deep Dive: Key Subrecipes
1. workflow_setup: Foundation First
| Input | Output |
|---|---|
rule_description | branch_name, standards_summary, repo_ready, mcp_panther |
This subrecipe handles all the foundational work:
Key responsibilities:
- Repository access verification
- Git branch creation and management
- Standards extraction from
AGENTS.md - Environment validation
- Panther MCP access testing
Output example:
{
"status": { "success": true },
"data": {
"branch_name": "ai/okta-suspicious-login",
"standards_summary": "Rules must use ai_ prefix, implement required functions...",
"repo_ready": true,
"mcp_panther": { "access_test_successful": true }
}
}
2. similar_rule_analyzer: Learning from Existing Patterns
| Input | Output |
|---|---|
rule_description, standards_summary, rule_type | similar_rules_found, rule_analysis, suggested_approach |
This subrecipe searches the repository for similar detection patterns:
# Search strategy by rule type:
- streaming rules: Search rules/<team>_rules/
- correlation rules: Search correlation_rules/<team>_correlation_rules/
- scheduled rules: Search queries/<team>_queries/
Key responsibilities:
- Search for existing rules with similar log sources and detection logic
- Prioritize team-created rules over upstream patterns
- Analyze implementation approaches and coding patterns
- Provide recommendations for new rule development
- Extract relevant context from similar implementations
Key insight: It prioritizes team-created rules (<team>_* directories) over upstream rules, ensuring consistency with established patterns.
Even without direct access to the detection engine, users can develop new detections by leveraging existing ones, along with our established standards and test suite.
3. schema_and_sample_events_analyzer: Data-Driven Detection Logic
| Input | Output |
|---|---|
rule_description, similar_rules_found | log_schemas, example_logs, field_mapping, panther_mcp_usage |
This subrecipe bridges the gap between detection requirements and implementation by leveraging Panther's MCP integration:
Key responsibilities:
- Log schema analysis using Panther MCP
- Sample event collection from data lakes
- Field mapping for detection logic
- Snowflake SQL query optimization
Smart data collection strategy:
- Parallel execution: Runs multiple Snowflake queries simultaneously rather than sequentially
- Query planning: Identifies all needed queries before execution to maximize efficiency
- Progressive sampling: Starts with small result sets (LIMIT 5), scales up as needed
- Critical boundaries: It explicitly cannot create rule files or run tests - its sole focus is understanding the data structure.
Output example:
{
"status": { "success": true },
"data": {
"log_schemas": [{
"log_type": "AWS.CloudTrail",
"schema_summary": "Contains eventName, sourceIPAddress, userIdentity fields",
"relevance": "Essential for detecting privilege escalation patterns"
}],
"example_logs": [{
"log_type": "AWS.CloudTrail",
"event_summary": "AssumeRole events with cross-account access",
"key_fields": ["eventName", "sourceIPAddress", "userIdentity.type"]
}],
"panther_mcp_usage": {
"mcp_used": true,
"log_schemas_referenced": true,
"data_lake_queries_performed": true
}
}
}
Fallback handling: When Panther MCP is unavailable, it intelligently uses similar rule analysis to infer schema structure, ensuring the workflow continues with reduced but functional capability.
4. rule_creator: The Implementation Engine
| Input | Output |
|---|---|
rule_description, similar_rules_found, rule_analysis, log_schemas, standards_summary | rule_files_created, rule_implementation, test_cases_created |
This is where the magic happens - this subrecipe generates the required files containing the detection logic, metadata and unit tests.
Smart log source validation:
- If schema analysis ran successfully → Use validated log types
- If schema analysis was skipped → Validate against known log types defined in pytests.
Example key principles:
- Always use default values for event fields
- Use case-insensitive matching for user-controlled fields
- Structure logic clearly with grouped conditions
- Prefer
any()andall()over multiple return statements
To illustrate, the following example provides guidance for the last bullet point:
💡 Code Quality Tip: Simplify Conditional Logic
❌ Avoid: Too Many Return Statements
# multiple returns make logic hard to follow
def rule(event) -> bool:
if event.deep_get("eventType", default="") != "user.session.start":
return False
if event.deep_get("outcome", "result", default="") != "SUCCESS":
return False
if event.deep_get("actor", "alternateId", default="").lower() == TARGET_USER.lower():
return True
return False✅ Preferred: Clear Structure with
any()andall()def rule(event) -> bool:
return all([
event.deep_get("eventType", default="") == "user.session.start",
event.deep_get("outcome", "result", default="") == "SUCCESS",
event.deep_get("actor", "alternateId", default="").lower() == TARGET_USER.lower()
])
5. testing_validator: Quality Assurance
| Input | Output |
|---|---|
rule_files_created | test_results, validation_status, issues_found |
This subrecipe serves as the critical quality gate, executing the mandatory testing pipeline that ensures every detection meets production standards.
Key responsibilities:
- Execute all mandatory testing commands from
AGENTS.md(e.g. linting, formatting and both unit and pytests) - Validate rule implementation against team standards
- Provide actionable feedback for fixing issues
- Ensure compliance with security and coding requirements
These checks ensure detections meet our standards, preventing subpar code from being merged. Should a check fail, the LLM will iterate, identifying and implementing necessary changes until compliance is achieved as part of the same recipe run.
Intelligent failure analysis: The subrecipe doesn't just run tests - it analyzes failures and provides specific guidance:
{
"test_results": {
"tests_passed": 3,
"tests_failed": 1,
"test_details": [{
"test_name": "make lint",
"status": "failed",
"message": "pylint: missing default value in deep_get() call"
}]
},
"recommendations": [
"Add default values to all deep_get() calls per AGENTS.md standards",
"Reference 'Core Coding Standards' section for proper error handling"
]
}
Output example:
{
"status": { "success": true },
"data": {
"test_results": {
"tests_passed": 4,
"tests_failed": 0,
"test_details": [
{ "test_name": "make fmt", "status": "passed", "message": "All files formatted correctly" },
{ "test_name": "make lint", "status": "passed", "message": "No linting issues found" },
{ "test_name": "make test", "status": "passed", "message": "Rule tests passed: 2/2" },
{ "test_name": "make pytest-all", "status": "passed", "message": "All unit tests passed" }
]
},
"validation_summary": "All mandatory tests passed. Rule ready for PR creation.",
"recommendations": []
}
}
6. pr_creator: Automated Pull Request Pipeline
| Input | Output |
|---|---|
rule_files_created, rule_description, branch_name, create_pr, panther_mcp_usage | pr_created, pr_url, pr_number, summary |
This subrecipe handles the final workflow step with full adherence to team standards:
Key responsibilities:
- Git branch management and commits
- PR template population with proper formatting
- Panther MCP usage tracking and reporting
- Draft PR creation for team review
Intelligent PR creation:
- Conditional execution: Only creates PRs when
create_pr=true, otherwise provides summary - Template compliance: Automatically populates PR templates from
AGENTS.mdstandards - MCP usage reporting: Documents whether Panther MCP was used in the workflow section (which is useful for PR reviewers to know)
Git operation standards:
- Never uses
--no-verifyflags - fixes issues rather than bypassing them - Follows commit message guidelines from team standards
- Ensures proper branch management and remote synchronization
Output example:
{
"status": { "success": true },
"data": {
"pr_url": "https://github.com/<org>/<team>-panther-content/pull/123",
"pr_number": 123,
"branch_name": "ai/aws-privilege-escalation",
"commit_hash": "abc123def",
"files_committed": ["rules/<team>_rules/ai_aws_privilege_escalation.py", "rules/<team>_rules/ai_aws_privilege_escalation.yml"]
}
}
Quality assurance: This subrecipe includes comprehensive error handling for git failures, PR creation issues, and template population problems, providing clear fallback instructions when automation fails.
Error Handling and Fail-Fast Design
This workflow implements sophisticated error handling with intelligent stopping points:
Standardized Response Schema
Every subrecipe uses a consistent JSON response format:
{
"status": {
"success": boolean,
"error": "Error message if failed",
"error_type": "categorized_error_type"
},
"data": { /* Actual response data */ },
"partial_results": { /* Optional partial data */ }
}
Failures
This workflow distinguishes between different types of failures. For example, each subrecipe’s response has an error_code field. When a failure occurs, the LLM categorizes the type of error encountered and surfaces this information to the main recipe so it can make a determination on what to do next.
As an example, rule_creator is configured with these error categories:
response:
json_schema:
type: object
properties:
status:
type: object
properties:
...
error_type:
type: string
enum: ["git_operation_failed", "pr_creation_failed", "template_population_failed", "validation_failed"]
description: "Category of error for debugging purposes"
...
If this subrecipe returns file_creation_failed, we shouldn’t move on to the testing_validator or pr_creator steps.
This fail-fast approach prevents wasted effort on meaningless subsequent steps.
Practical Usage Examples
Basic Usage: Fast Detection Creation
# Create a detection without creating a PR or similar rule/Panther MCP analysis
goose run --recipe recipe.yaml \
--params skip_similar_rules_check=true \
--params skip_panther_mcp=true \
--params rule_description="Create an AWS CloudTrail detection to identify new regions being enabled without any associated errorCodes"
Comprehensive Analysis Mode
# Full workflow with schema/event sampling and automatic PR creation
goose run --recipe recipe.yaml --interactive \
--params skip_similar_rules_check=true \
--params skip_panther_mcp=false \
--params create_pr=true \
--params rule_description="Create a Panther rule that will detect when the user fbar@block.xyz successfully logs in to Okta from a Windows system"
Standards Compliance and Quality Assurance
The recipe system ensures compliance with team standards through:
Automated Standards Extraction
The workflow_setup subrecipe extracts key requirements from AGENTS.md:
- File naming conventions (
ai_prefix for AI-created rules) - Required Python functions and error handling patterns
- Testing requirements and validation commands
- PR creation standards and templates
Built-in Quality Checks
- Code formatting: Automatic formatting execution
- Linting: Comprehensive linting validation
- Testing: Mandatory test suite execution
- Security: No PII in test cases (based on LLM's determination) and proper error handling (e.g. ensuring default values are returned)
- Consistency: Standardized file structures and naming
Pull Request Automation
The pr_creator subrecipe follows team standards:
- Proper branch naming (e.g.
ai/<description>) - Template-based PR descriptions
- Draft mode for review
- Comprehensive change summaries
Panther MCP Integration
The workflow integrates with Panther's Model Context Protocol (MCP) for:
- Schema analysis: Understanding log structure and available fields
- Sample data collection: Gathering realistic test data from data lakes
- Field mapping: Identifying key fields for detection logic
Benefits and Impact
For Security Teams
- Faster detection development: Minutes instead of hours
- Consistent quality: Automated adherence to standards
- Reduced errors: Comprehensive testing before deployment
- Knowledge sharing: Similar rule analysis spreads best practices
For AI Development
- Modular architecture: Easy to modify individual components
- Clear debugging: Specific failure points and error categories
- Predictable behavior: Consistent outputs across runs
- Maintainable code: Well-defined boundaries and responsibilities
For Organizations
- Accessibility: Empowers users to create detections without deep knowledge of the underlying detection engine
- Scalable security: Rapid response to new threats
- Quality assurance: Built-in testing and validation
- Documentation: Automatic PR creation with proper context
- Compliance: Adherence to security and development standards
Conclusion
Goose's recipe and subrecipe system represents a significant advancement in AI-assisted security detection development. By breaking complex workflows into specialized, composable components, teams can achieve:
- Higher quality detections through automated testing and validation
- Faster development cycles with intelligent optimization
- Better consistency through standardized processes
- Easier maintenance with modular, well-defined components
The detection creation recipe demonstrates how thoughtful architecture and clear separation of concerns can transform a complex, error-prone manual process into a reliable, automated workflow.
Whether you're building your first Goose recipe or looking to optimize existing workflows, the patterns and principles outlined here provide a solid foundation for successful automation.
Best Practices and Lessons Learned
Instruction Formatting & Clarity
- Prefer concise bullet points over dense paragraphs to keep instructions skimmable.
- Use emphasis (e.g. *bold*, ALL CAPS) to highlight important constraints or behaviors.
- Write task-specific instructions with clear exit criteria — avoid asking the agent to do more than it needs to.
Structure & Logic in Prompts
- Use explicit logic in templating (e.g., Jinja): define yes/no flags rather than relying on the LLM to infer conditions.
- Provide structured output (e.g. JSON) where needed to support downstream recipes or tools.
- Avoid vague labels — use neutral and consistent verbiage (e.g., “correct/incorrect” instead of “good/bad”).
Validation & Guardrails
- Add code snippets or examples to illustrate expected behavior.
- Use checklists to help the AI verify whether it followed all required steps.
- Incorporate pytests or other test gates to catch issues early. Avoid bypasses like
--no-verifyongitcommands.- Let the system self-correct where possible.
- Codify standards so updates are required to pass tests before a PR can be pushed.
Knowledge Sharing & Context Management
- Provide strong examples that the agent can learn from, reducing reliance on querying the data lake.
- Maintain a central reference (e.g.
AGENTS.md) for all AI agents:- Users may want to contribute outside of your traditional development workflow
- Link steps or sections in
.goosehints,CLAUDE.md,.cursor/rules/*, etc., back to this file. - Consider having an agent help structure
AGENTS.mdfor easier parsing and reuse across agents.
Workflow Design
- Use PR templates and guidelines to standardize formatting and expectations for AI-generated contributions.
- Leverage a shared context across recipes, but isolate workflows using separate context windows where appropriate.
- Allows output passing and parallel execution, while supporting separation of duties between steps.