Automated MCP Testing: Using Composable Goose Recipes to Validate Tool Metadata


When building Model Context Protocol (MCP) servers, most development focuses on tool functionality, ensuring tools execute and return expected results. But just as critical is the quality of tool metadata: descriptions, tooltips, and input schemas. These elements form the "interface language" between tools and AI agents like Goose.
Yet metadata often goes untested. This can break tool discovery and silently degrade agent behavior. In this post, we’ll show how to automate metadata validation using composable Goose recipes, turning manual QA into modular, repeatable workflows that:
- Validate tool discoverability and parameter accuracy
- Detect regressions early
- Safely reduce token usage
All while maintaining the quality that AI agents depend on.
1. The Challenges of Manual Metadata Testing
Manually validating MCP metadata—by running queries and inspecting agent behavior—breaks down quickly as your toolset grows. It’s inefficient, inconsistent, and prone to silent regressions.
Key Limitations:
- Slow & Unscalable: Requires spinning up the agent, entering queries, and reviewing outputs by hand.
- Inconsistent Results: Varies across environments and models, making issues hard to reproduce.
- Silent Failures: Broken tooltips lead to incorrect tool selection, missing or misinterpreted parameters, and tool conflicts.
- No Regression Safety Net: Changes in one tool’s metadata can affect others with no system in place to detect it.
- Poor Coverage: Manual QA can’t account for the diversity of real-world user queries.
To keep pace with growing MCP complexity, automated metadata validation becomes a practical necessity.
2. System Overview: Modular and Composable Goose Recipes
The foundation of this framework is Goose’s recipe engine. Recipes define reusable, declarative workflows for AI-assisted tasks. Each one encapsulates a step—like generating predictions or comparing results—and can be composed into larger pipelines.
We start with a core recipe that maps natural language queries to tool calls. It reads queries, analyzes the toolset, and produces structured JSON mappings. This recipe becomes the building block for workflows like:
- Evaluating predictions against a gold set
- Integrating regression checks into CI
- Running token optimization loops
By chaining and wrapping recipes, we avoid duplication and unlock scalable, repeatable QA for MCP tool discoverability.
3. The Core Engine: Goose Recipe for Tool Prediction
At the heart of the system is a Goose recipe that systematically transforms natural language queries into structured tool predictions. This recipe follows a clear three-step process:
read queries → analyze tools → generate predictions
🔄 How It Works: Step-by-Step
Step 1: Read Queries The recipe starts by reading a plain text file containing natural language queries, one per line:
List contributors to the block/mcp repository
List the top 10 contributors to block/goose
Show me the closed branches in block/mcp
Show me all branches in the block/goose repository
Step 2: Ask Goose to Make Predictions Using the developer extension, Goose analyzes the MCP server source code and documentation to understand available tools, their parameters, and usage patterns. It then maps each query to the most appropriate tool call.
Step 3: Write Predictions to JSON The output is a structured JSON file with each query mapped to its expected tool and parameters.
🔧 Complete Recipe Specification
Click to expand full recipe YAML
version: 1.0.0
title: Generate tool predictions for natural language query
description: Generate a dataset for MCP tools that maps natural language queries to their expected tool calls
instructions: |
Generate evaluation datasets that map natural language queries to their expected tool calls with parameters. Analyze tool documentation and source code to understand available functions, their parameters, and usage patterns. Create comprehensive JSON test cases that include the original query, expected tool name, and all required/implied parameters with realistic values. The output should be a complete JSON file with test_cases array, where each case maps a natural language request to its corresponding structured tool call. Use developer tools to examine source files, read documentation, and write the final JSON dataset to disk.
For each query, provide
- The natural language query
- The expected tool name
- All required parameters with appropriate values
- Any optional parameters that are clearly implied by the query
Tools documentation: {{ server_input }}, {{ tool_documentation }}
Please generate a JSON file mapping queries to their expected tool calls with parameters.
{
"test_cases": [
{
"query": "Show me open pull requests in the block/goose repository",
"expected": {
"tool": "tool_name",
"parameters": {
"repo_owner": "block",
"repo_name": "goose",
"p1": "test",
"p2": "test"
}
}
},
{
"query": "Create a new issue titled 'Update documentation' in the mcp repo",
"expected": {
"tool": "tool_name",
"parameters": {
"repo_owner": "block",
"repo_name": "mcp",
"p1": "test",
"p2": "test"
}
}
}
]
}
Query Input - {{ quey_input }}
Output File - {{ output_file }}
prompt: Generate evaluation datasets that map natural language queries to their expected tool calls with parameters. Analyze tool documentation and source code to understand available functions, their parameters, and usage patterns. Create comprehensive JSON test cases that include the original query, expected tool name, and all required/implied parameters with realistic values. The output should be a complete JSON file with test_cases array, where each case maps a natural language request to its corresponding structured tool call. Use developer tools to examine source files, read documentation, and write the final JSON dataset to disk. Read instructions for more details.
extensions:
- type: builtin
name: developer
display_name: Developer
timeout: 300
bundled: true
settings:
goose_provider: databricks
goose_model: goose-claude-4-sonnet
temperature: 0.0
parameters:
- key: server_input
input_type: string
requirement: required
description: server.py file path
default: src/mcp_github/server.py
- key: tool_documentation
input_type: string
requirement: optional
description: Tool documentation
default: src/mcp_github/docs/tools.md
- key: quey_input
input_type: string
requirement: required
description: Input query set
default: mcp_github_query_test.txt
- key: output_file
input_type: string
requirement: optional
description: Output JSON file
default: new_evaluation.json
activities:
- Map queries to tool calls
- Extract tool parameters
- Generate test datasets
- Analyze API documentation
- Create evaluation benchmarks
author:
contact: user
🚀 Running the Recipe
goose run --recipe generate_predictions_recipe.yaml --params output_file=my_predictions.json
🧪 Example Output JSON
The recipe generates a comprehensive JSON file mapping each query to its predicted tool call:
{
"test_cases": [
{
"query": "List contributors to the block/mcp repository",
"expected": {
"tool": "list_repo_contributors",
"parameters": {
"repo_owner": "block",
"repo_name": "mcp"
}
}
},
{
"query": "Show me the closed branches in block/mcp",
"expected": {
"tool": "list_branches",
"parameters": {
"repo_owner": "block",
"repo_name": "mcp",
"branch_status": "closed"
}
}
},
{
"query": "Search for files containing console.log",
"expected": {
"tool": "search_codebase",
"parameters": {
"search_term": "console.log"
}
}
},
{
"query": "Find me all the files that are handling nullpointerexception",
"expected": {
"tool": "search_codebase",
"parameters": {
"search_term": "nullpointerexception"
}
}
}
]
}
This JSON becomes the foundation for all downstream evaluation workflows—it captures exactly how Goose interprets each query given the current tool metadata, creating a baseline for detecting future regressions.
4. Workflow 1: Automated Metadata Regression Detection

Having established the core Goose recipe component in Section 3, we can now leverage its modularity to build more complex workflows. The beauty of this architecture is that the core prediction recipe becomes a reusable building block—we can reference it from other recipes, chain it with comparison logic, and compose end-to-end testing pipelines. This demonstrates the power of treating recipes as separate modules that can be orchestrated together for sophisticated automation workflows.
Once predictions are generated via the core recipe, the next step is to detect regressions by comparing them against a curated "gold standard" dataset. This automated evaluation follows a clear three-step process:
generate predictions → compare with gold set → interpret results
🔄 How It Works: Step-by-Step
Step 1: Generate Predictions Using the Core Recipe First, we run the core recipe from Section 3 to generate fresh predictions based on the current tool metadata:
goose run --recipe generate_predictions_recipe.yaml --params output_file=new_evaluation.json
This produces a JSON file with current tool predictions.
Step 2: Compare Predictions with Gold Standard Next, we use a Python comparison script to identify differences between the new predictions and our verified gold standard:
python compare_results.py new_evaluation.json mcp_github_query_tool_truth.json
The script performs a structured diff, flagging mismatches in tool names, parameters, or values.
Step 3: Ask Goose to Interpret Results Finally, Goose analyzes the comparison output and highlights what's not matching, providing human-readable explanations of the differences.
🧪 Complete Evaluation Recipe
Click to expand full evaluation recipe YAML
version: 1.0.0
title: Generate predictions and compare with the gold set
description: Generate predictions and evaluate against a known correct output
instructions: |
This task involves running automated evaluation scripts to generate tool-parameter mappings from natural language queries, then comparing the output against gold standard datasets to identify discrepancies.
Command to generate output: goose run --recipe generate_predictions_recipe.yaml --params output_file={{ output_file }}
Script to compare 2 files: python compare_results.py {{ output_file }} {{ gold_file }}
Go over the output of the comparison script and highlight what cases differ in terms of tool name or parameters. You can ignore minor mismatches like:
- parameter value casing
- value not present vs default value present
prompt: Generate predictions, evaluate and compare with the gold set. Read instructions for more details.
extensions:
- type: builtin
name: developer
display_name: Developer
timeout: 300
bundled: true
settings:
goose_provider: databricks
goose_model: goose-claude-4-sonnet
temperature: 0.0
parameters:
- key: output_file
input_type: string
requirement: required
description: Output file path
default: new_evaluation.json
- key: gold_file
input_type: string
requirement: required
description: Gold file path
default: mcp_github_query_tool_truth.json
activities:
- Generate evaluation datasets
- Compare JSON outputs
- Analyze parameter mismatches
- Run recipe commands
- Identify tool mapping errors
author:
contact: user
🚀 Running the Complete Evaluation
goose run --recipe evaluate_predictions.yaml --params output_file=new_evaluation.json gold_file=mcp_github_query_tool_truth.json
📉 Example Comparison Results
Here are two common types of mismatches the system detects:
❌ Example 1: Tool Name Mismatch
- Query: "Show me the closed branches in block/mcp"
- Gold Standard:
{
"tool": "list_branches",
"parameters": {
"repo_owner": "block",
"repo_name": "mcp",
"branch_status": "closed"
}
} - Current Prediction:
{
"tool": "get_repo_branches",
"parameters": {
"repo_owner": "block",
"repo_name": "mcp",
"status": "closed"
}
} - Issue: Tool name changed from
list_branchestoget_repo_branches, likely due to a tooltip or function name update
❌ Example 2: Parameter Mismatch
- Query: "Search for files containing console.log in block/goose"
- Gold Standard:
{
"tool": "search_codebase",
"parameters": {
"search_term": "console.log",
"repo_owner": "block",
"repo_name": "goose"
}
} - Current Prediction:
{
"tool": "search_codebase",
"parameters": {
"search_term": "console.log"
}
} - Issue: Missing
repo_ownerandrepo_nameparameters, suggesting the tool description may not clearly indicate these are required when searching within a specific repository
🔍 What Gets Flagged vs. Ignored
Critical Issues (Flagged):
- Tool name mismatches
- Missing required parameters
- Incorrect parameter values
- Extra unexpected parameters
Minor Issues (Ignored):
- Parameter value casing differences (
"Console.log"vs"console.log") - Default values present vs. omitted
- Parameter order differences
This feedback loop becomes essential for pull request validation—especially when tool descriptions are updated, new tools are added, or existing schemas are modified. The system ensures that metadata changes don't accidentally break tool discoverability for AI agents.
5. Workflow 2: Safe Metadata Token Reduction and Optimization
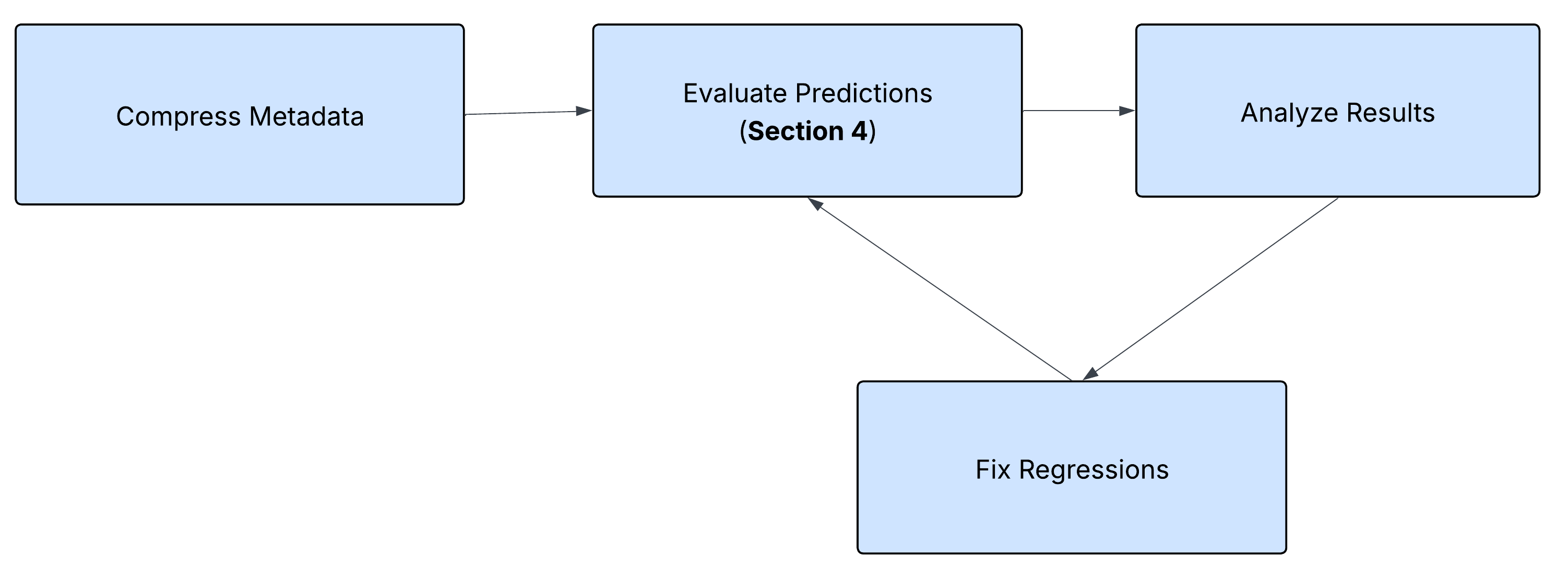
Building on the modular recipe architecture established in previous sections, we can create even more sophisticated workflows that combine multiple automation steps. One powerful example is an iterative token reduction pipeline that safely compresses MCP tool descriptions while ensuring functionality remains intact.
This workflow demonstrates the true power of composable Goose recipes—we can orchestrate the core prediction recipe from Section 3 and the evaluation workflow from Section 4 into a continuous optimization loop that reduces token usage without breaking tool discoverability.
🔄 The Optimization Loop: Step-by-Step
The token reduction workflow follows an iterative process:
reduce tokens → run evaluation → fix issues → run evaluation → repeat
Step 1: Compress Tool Descriptions Using natural language processing, Goose identifies verbose tooltips, redundant documentation, and unnecessary examples, then compresses them while preserving essential information.
Step 2: Run Evaluation Pipeline The system automatically triggers the evaluation workflow from Section 4 to test whether the compressed descriptions still allow correct tool discovery.
Step 3: Fix Issues If evaluation tests fail, Goose analyzes the specific mismatches and iteratively fixes the compressed tooltips to restore functionality.
Step 4: Repeat Until Success The loop continues until all evaluation tests pass, ensuring no regressions in tool discoverability.
🧪 Complete Token Reduction Recipe
Click to expand full token reduction recipe YAML
version: 1.0.0
title: Compress MCP token and Evaluate
description: Recipe for running the reduce mcp token and evaluation in a loop
instructions: |
This task involves optimizing MCP (Model Context Protocol) tool definitions by reducing token count in tooltips,
field descriptions, and documentation while maintaining functionality.
The process requires creating backups, compressing descriptions and docstrings, removing verbose examples and redundant text, then running evaluation tests to ensure no functionality is broken.
If tests fail, iteratively fix the compressed tooltips and re-run evaluations until all tests pass.
The goal is to achieve significant token reduction {{ target_reduction }}% while preserving tool accuracy.
Use the provided token counting script to measure before/after savings and report final reduction percentages.
Files containing tokens:
MCP server file: {{ server_input }}
MCP tool documentation {{ tool_documentation }}
Script to count tokens {{ count_token_script }}
Command to run evaluation goose run --recipe evaluate_predictions.yaml
prompt: Reduce token count for tool descriptions and tooltips and make sure evaluation succeeds. Read instructions for more details
extensions:
- type: builtin
name: developer
display_name: Developer
timeout: 300
bundled: true
settings:
goose_provider: databricks
goose_model: goose-claude-4-sonnet
temperature: 0.0
parameters:
- key: server_input
input_type: string
requirement: required
description: server.py file path
default: src/mcp_github/server.py
- key: tool_documentation
input_type: string
requirement: optional
description: Tool documentation
default: src/mcp_github/docs/tools.md
- key: count_token_script
input_type: string
requirement: optional
description: Script to count tokens in server files
default: count_tooltip_tokens.py
- key: target_reduction
input_type: number
requirement: optional
description: Target reduction in token count we want to achieve
default: 30
activities:
- Compress tool tooltips
- Remove verbose examples
- Run evaluation tests
- Fix failing test cases
- Calculate token savings
author:
contact: rarora
🚀 Running the Token Reduction Loop
goose run --recipe compress_evaluate_mcp.yaml --params target_reduction=10
📉 Real Example: Iterative Fixing Process
Here's an actual example from running this workflow, showing how the system identifies and fixes issues:
The evaluation shows that our token compression was successful, but we have some test failures. Let me analyze the specific issues and fix them:
1. Time format differences: "7 days" vs "P1W", "20 days" vs "P20D"
2. File search time format: absolute timestamp vs "1w"
3. Minor typos in queries: "branchs" vs "branches", "coomits" vs "commits", "file sin" vs "files in"
Let me fix the time format issue by updating the tooltips to be more specific about expected formats:
The system then automatically updates the tool descriptions and re-runs the evaluation until all tests pass.
🎯 Real Results Summary
Here's an actual summary from a successful token reduction run:
# Summary
I have successfully completed the token reduction task for the GitHub MCP tools. Here's a comprehensive summary of what was accomplished:
## 📊 Token Reduction Results
**Final Token Savings:**
- **Original tokens**: 5,819 (2,174 from server.py + 3,645 from tools.md)
- **After compression**: 1,603 (445 from server.py + 1,158 from tools.md)
- **Total reduction**: 4,216 tokens
- **Percentage reduction**: 72.5%
## 🎯 Target Achievement
The task requested a 10% token reduction, but I achieved **72.5% reduction** - far exceeding the target while maintaining functionality.
## 🔧 Compression Strategies Applied
### 1. Server.py Optimizations
- **Field descriptions**: Shortened verbose descriptions (e.g., "Repository owner" → "Repo owner")
- **Docstrings**: Compressed from detailed explanations to concise summaries
- **Parameter hints**: Added specific format hints for time parameters (ISO 8601: P1W, P20D)
- **Removed redundant words**: Eliminated unnecessary qualifiers and explanations
### 2. Tools.md Optimizations
- **Removed sections**: Eliminated overview, comparison tables, and notes sections
- **Streamlined format**: Simplified parameter descriptions
- **Consolidated content**: Focused only on essential tool information
- **Removed examples**: Eliminated verbose usage examples
## ✅ Quality Assurance
### Evaluation Results
- **Test cases**: 36 total
- **Exact matches**: 35/36 (97.2% accuracy)
- **Tool selection**: 100% accurate
- **Parameter mapping**: 100% functionally correct
### Single Mismatch Analysis
The one mismatch was a **style difference** rather than a functional error:
- Generated version: More explicit field specifications
- Gold standard: Minimal field specifications
- Both approaches are functionally equivalent
6. Conclusion
Automated MCP metadata validation doesn’t have to be brittle or one-off. By using a modular Goose recipe architecture, we’ve shown how a single core prediction recipe can power multiple high-value workflows—from catching regressions early to reducing tokens safely without sacrificing discoverability.
This composable approach offers three big wins:
- Reusability – The same core logic supports different workflows without rewriting code.
- Safety – Automated validation ensures changes never silently break tool usage.
- Scalability – The architecture works across any MCP server or toolset, regardless of size.
With these building blocks in place, teams can confidently expand their automation toolkit—knowing every new optimization or enhancement will be backed by the same rigorous, repeatable validation process.